通过请求和响应的交换达成通信
HTTP协议规定,请求从客户端发出,最后服务器端响应该请求并返回,换句话说,肯定是先从客户端开始建立通信的,服务端在没有接收到接收到请求之前不会发送响应。下面是一个简单的例子: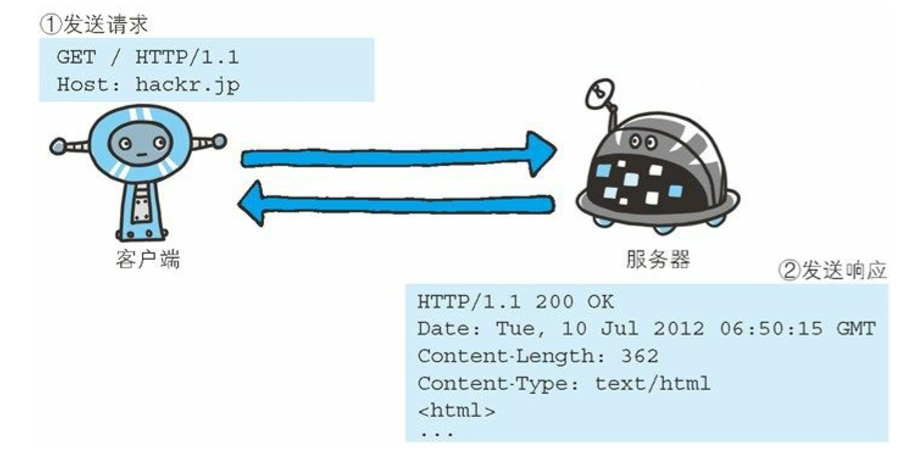
下面是从客户端发送给某个HTTP服务器的请求报文中的内容
1 | GET /index.htm HTTP/1.1 |
起始行开头的GET表示请求访问服务器的类型,称为方法(method)。随后的字符串/index.htm指明了请求访问的资源对象,也叫做请求的URI。最后的HTTP/1.1即HTTP的版本号,用来提示客户端使用的HTTP协议功能。请求报文是由请求方法、请求URI、协议版本、可选的请求首部字段和内容实体构成的。
综合来看,这段请求内容的意思是:请求访问某台HTTP服务器上的/index.htm页面资源。
接收到请求的服务器,会将请求内容的处理结果以响应的形式返回。
1 | HTTP/1.1 200 OK |
在起始行开头的HTTP/1.1表示服务器对应的HTTP版本,紧挨着的200 OK表示请求的处理结果的状态码和原因短语。下一行显示了创建响应的日期时间,是首部字段内的一个属性。接着以一空行分隔,之后的内容称为资源实体的主体。响应报文基本上由协议版本、状态码、用以解释状态码的原因短语、可选的响应首部字段以及实体主体构成。
告知服务器意图的HTTP方法
下面我们介绍合同HTTP/1.1中可使用的方法。
GET:获取资源
GET方法用来请求访问已被URI识别的资源。指定的资源经服务器端解析后返回响应内容。
POST:传输实体主体
POST方法用来传输实体的主体。
虽然用GET方法也可以传输实体的主体,但一般不用GET方法进行传输,而是用POST方法。虽说POST的功能与GET很相似,但POST的主要目的并不是获取响应的主体内容。
PUT:传输文件
PUT方法用来传输文件。就像FTP协议的文件上传一样,要求在请求报文的主体中包含文件内容,然后保存到请求URI指定的位置。
但是鉴于HTTP/1.1的PUT方法自身不带验证机制,任何人都可以上传文件,存在安全性问题,因此一般的Web网站不使用该方法。
HEAD:获得报文首部
HEAD方法和GET方法一样,只是不返回报文主体部分。用于确认URI的有效性及资源更新的日期时间等。
DELETE:删除文件
DELETE方法用来删除文件,是与PUT相反的方法。DELETE方法按请求URI删除指定的资源。
但是HTTP/1.1的DELETE方法本身和PUT方法一样不带验证机制,所以一般的Web网站也不使用DELETE方法。
OPTIONS:询问支持的方法
OPTIONS方法用来查询针对请求URI指定的资源支持的方法。
TRACE:追踪路径
TRACE方法是让Web服务器端将之前的请求通信返回给客户端的方法。发送请求时,在Max-Forwards首部字段中填入数值,每经过一个服务器端就将该数字减1,当数值刚好减到0时,就停止继续传输,最后接收到请求的服务器端则返回状态码200 OK的响应。
客户端通过TRACE方法可以查询发送出去的请求是怎样被加工修改/篡改的。这是因为,请求想要连接到源目标服务器可能会通过代理中转,TRACE方法用来确认连接过程中发生的一系列操作。
但是TRACE方法本来就不怎么常用,再加上它容易引发XST(跨站追踪)攻击,通常就更不会用到了。
CONNECT:要求用隧道协议连接代理
CONNECT方法要求在与代理服务器通信时建立隧道,实现用隧道协议进行TCP通信。主要使用SSL和TLS协议把通信内容加密后经网络隧道传输。
持久连接节省通信量
HTTP协议的初始化版本中,每进行一次HTTP通信就要断开一次TCP连接。这也就是短连接。
持久连接(长连接)
为了解决TCP连接的问题,HTTP/1.1和一部分的HTTP/1.0想出了持久连接的方法,也就是长连接。
持久连接的特点是,只要任意一端没有明确的提出断开连接,则保持TCP连接状态。
持久连接的好处在于减少了TCP连接的重复建立和断开所造成的额外开销,减轻了服务器端的负载。另外,减少开销的那部分时间,使HTTP请求和响应能够更早的结束,这样Web页面的显示速度也就相应提高了。
在HTTP/1.1中,所有的连接默认都是持久连接,但是在HTTP/1.0中并未标准化。虽然有一部分服务器通过非标准的手段实现了持久连接,但服务器端不一定能够支持持久连接。毫无疑问,除了服务器端,客户端也需要支持持久连接。
管线化
持久连接是的多数请求以管线化方式发送成为可能。从前发送请求后需等待并收到响应,才能发送下一个请求。管线化技术出现后,不用等待响应亦可直接发送下一个请求。
这样就能够做到同时并行发送多个请求,而不需要一个接一个的等待响应了。
使用Cookie的状态管理
HTTP是无状态协议,它不对之前发生过的请求和响应的状态进行管理,也就是说,无法根据之前的状态进行本次的请求处理。
不可否认,无状态协议当然有它的优点,由于不必保存状态,自然可减少服务器的CPU及内存资源的消耗。从另一侧面来说,也正是因为HTTP协议本身是非常简单的,所以才会被应用在各种场景里。
保留无状态协议这个特征的同时又要解决类似的矛盾问题,于是引入了Cookie技术。Cookie技术通过在请求和响应报文中写入Cookie信息来控制客户端的状态。
Cookie会根据从服务器发送的响应报文内的一个叫做Set-Cookie的首部字段信息,通知客户端保存Cookie。当下次客户端再往服务器发送请求时,客户端会自动在请求报文中加入Cookie的值后发送出去。
服务端发现客户端发送过来的Cookie后,会去检查究竟是从哪一个客户端发来的请求,然后对比服务器上的记录,最后得到之前的状态信息。
HTTP报文
用于HTTP协议交互的信息被称为HTTP报文。请求端(客户端)的HTTP报文叫做请求报文,响应端(服务器端)的叫做响应报文。HTTP报文本身是由多行数据构成的字符串文本。
HTTP报文大致可分为报文首部和报文主体两块。两者由最初出现的空行来划分。通常并不一定要有报文主体。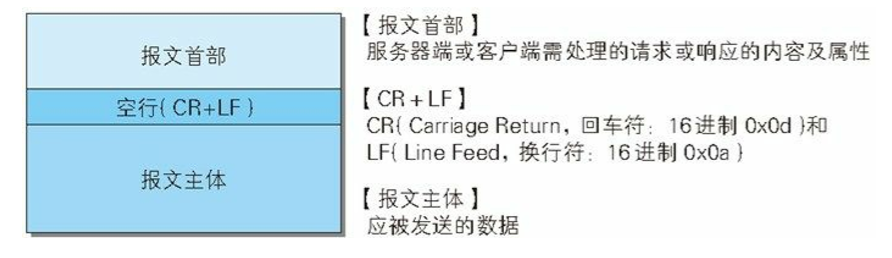
请求报文及响应报文的结构
下面是请求报文和响应报文的结构: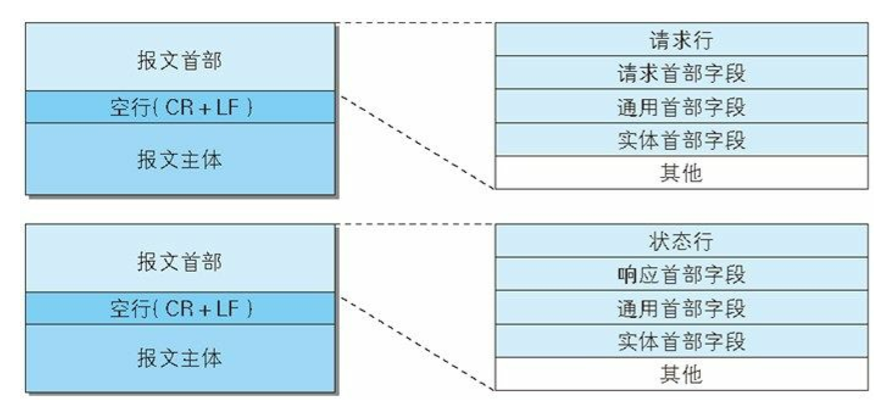
请求报文和响应报文的首部内容由以下数据组成。
- 请求行:包含用于请求的方法,请求URI和HTTP版本。
- 状态行:包含表明响应结果的状态码,原因短语和HTTP版本。
- 首部字段:包含表示请求和响应的各种条件和属性的各类首部。一般有4种首部,分别是:通用首部、请求首部、响应首部和实体首部。
- 其他:可能包含HTTP的RFC里未定义的首部,例如Cookie等。
编码提升传输速率
压缩传输的内容编码
HTTP报文的主题用于传输请求或响应的实体主体。向待发送邮件内增加附件时,为了使邮件容量变小,我们会先用ZIP压缩文件之后再添加附件发送。HTTP协议中有一种被称为内容编码的功能也能进行类似的操作。
内容编码指明应用在实体内容上的编码格式,并保持实体信息原样压缩。内容编码后的实体由客户端接收并负责解码。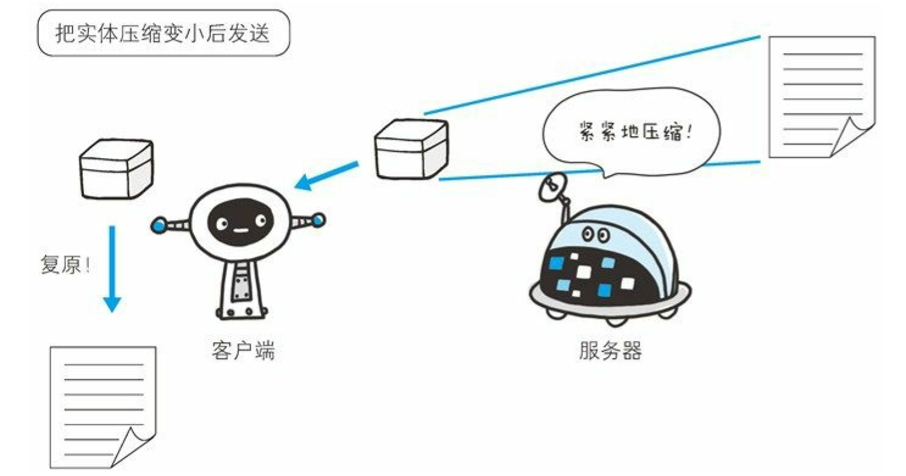
常用的内容编码有以下几种:
- gzip(GUN zip)
- compress(UNIX系统的标准压缩)
- deflate(zlib)
- identity(不进行编码)
分割发送的分块传输编码
在HTTP通信过程中,请求的编码实体资源尚未全部传输完成之前,浏览器无法显示请求页面。在传输大容量数据时,通过把数据分割成多块,能够让浏览器逐步显示页面。
这种把实体主体分块的功能称为分块传输编码。分块传输编码会将实体主体分成多个部分(块)。每一块都会用十六进制来标记块的大小,而实体主体的最后一块会使用“0(CR+LF)”来标记。
使用分块传输编码的实体主体由接收的客户端负责解码,恢复到编码前的实体主体。在HTTP/1.1中存在一种称为传输编码的机制,它可以在通信时按某种编码方式传输,但只定义作用于分块传输编码中。
发送多种数据的多部分对象集合
发送邮件时,我们可以在邮件里写入文字并添加多份附件。这是因为采用了MIME机制,它允许邮件处理文本、图片、视频等多种不同类型的数据。相应的HTTP协议中也采纳了多部分对象集合,发送的一份报文主体内可含有多类型实体。通常是在图片或文本文件等上传时使用。
多部分对象集合包含的对象如下:
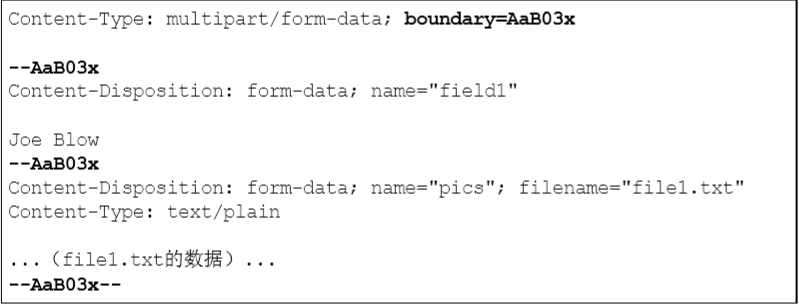
- multipart/form-data:在Web表单文件上传时。
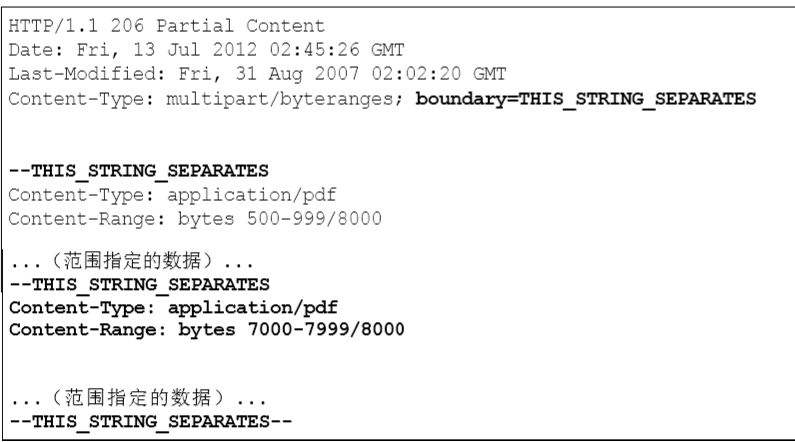
- multipart/byteranges:状态码206(Partial Content,部分内容)响应报文包含了多个范围的内容时使用。
在HTTP报文中使用多部分对象集合时,需要在首部字段里加上Content-type。使用boundary字符串来划分多部分对象集合指明的各类实体。在boundary字符串指定的各个实体的起始行之前插入“–”标记,而在多部分对象集合对应的字符串最后插入“–”标记作为结束。
多部分对象集合的每个部分类型中,都可以含有首部字段。另外可以在某个部分中嵌套使用多部份对象集合。
获取部分内容的范围请求
HTTP实现了为需要指定下载的实体范围。像这样,指定范围发送的请求叫做范围请求。对一份10000字节大小的资源,如果使用范围请求,可以只请求5001-10000字节内的资源。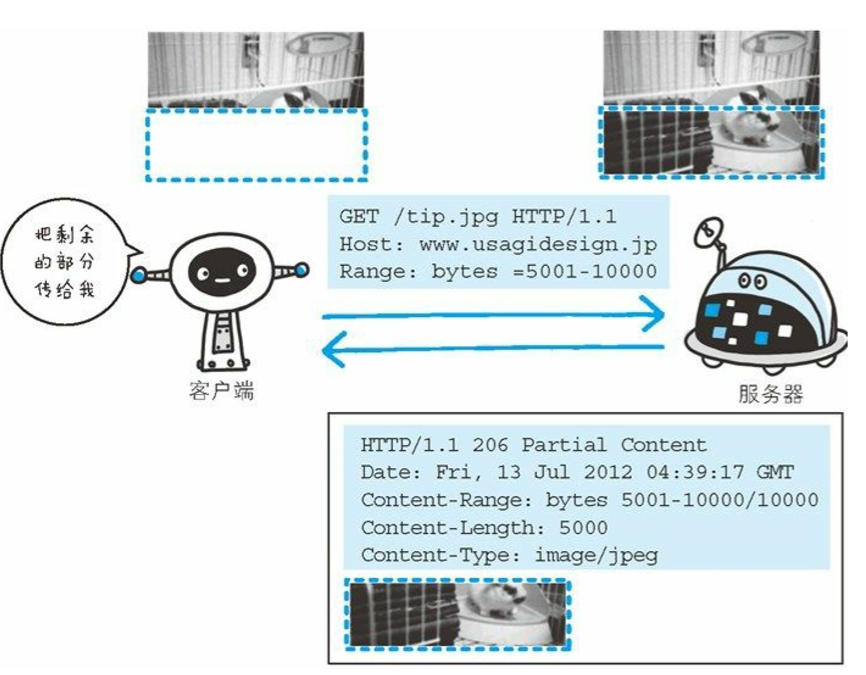
执行范围请求时,会用到首部字段Range来指定资源的byte范围。byte范围的指定形式如下:
1 | 5001~10 000 字节 |
针对范围请求,响应会返回状态码206 Partial Content的响应报文。另外,对于多重范围的范围请求,响应会在首部字段Content-Type标明multipart/byteranges后返回响应报文。
如果服务器端无法响应范围请求,则会返回状态码200 OK和完整的实体内容。
内容协商返回最合适的内容。
内容协商机制是指客户端和服务器端就响应的资源内容进行交涉,然后提供给客户端最为合适的资源。内容协商会以语言、字符集、编码方式等为基准判断响应的资源。
包含在请求报文中的某些首部字段就是判断的基准:
- Accept
- Accept-Charset
- Accept-Encoding
- Accept-Language
- Content-Language