ArrayList的数据结构
ArrayList往往被人用来与LinkedList对比,它们俩最重要的差异之一就是:ArrayList的底层是由数组组成的,而LinkedList的底层则是由链表组成,对于LinkedList不再多赘述,具体可以看一下LinkedList的文章。回到ArrayList中来,其实现的数据结构是一个名为elementData的Object数组,可以存放所有Object对象,因此我们对ArrayList类的实例的所有的操作底层都是基于这个数组的。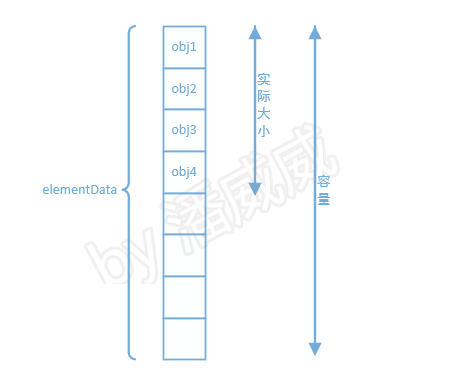
顶部注释
List接口的可调整大小的数组实现。 实现所有可选列表操作,并允许所有元素,包括null 。 除了实现List接口之外,该类还提供了一些方法来处理内部用于存储列表的数组的大小。 (这个类大致相当于Vector ,除了它是不同步的。)
该size , isEmpty , get , set , iterator ,并listIterator操作在固定时间内运行。 add操作以摊销的常数运行 ,即添加n个元素需要O(n)个时间。 所有其他操作都以线性时间运行(粗略地说)。 与LinkedList实现相比,常数因子较低。每个ArrayList实例都有一个容量 。 容量是用于存储列表中的元素的数组的大小。 它总是至少与列表大小一样大。 当元素添加到ArrayList时,其容量会自动增长。 没有规定增长政策的细节,除了添加元素具有不变的摊销时间成本。
在使用ensureCapacity操作添加大量元素之前,应用程序可以增加ArrayList实例的容量。 这可能会减少增量重新分配的数量。
请注意,此实现不同步。 如果多个线程同时访问ArrayList实例,并且至少有一个线程在结构上修改列表,则必须在外部进行同步。 (结构修改是添加或删除一个或多个元素的任何操作,或明确调整后台数组的大小;仅设置元素的值不是结构修改。)这通常是通过在一些自然地封装了名单。 如果没有这样的对象存在,列表应该使用Collections.synchronizedList方法“包装”。 这最好在创建时完成,以防止意外的不同步访问列表:
List list = Collections.synchronizedList(new ArrayList(…)); 由这个类的iterator和listIterator方法返回的迭代器是故障快速的 :如果列表在迭代器创建之后的任何时间被结构地修改,除了通过迭代器自己的remove或add方法之外,迭代器将抛出一个ConcurrentModificationException 。 因此,面对并发修改,迭代器将快速而干净地失败,而不是在未来未确定的时间冒着任意的非确定性行为。
请注意,迭代器的故障快速行为无法保证,因为一般来说,在不同步并发修改的情况下,无法做出任何硬性保证。 失败快速的迭代器ConcurrentModificationException扔出ConcurrentModificationException 。 因此,编写依赖于此异常的程序的正确性将是错误的: 迭代器的故障快速行为应仅用于检测错误。
这个类是Java Collections Framework的成员。
总结上面的顶部注释可以得到以下几点:
- 底部实现:可调整大小的数组实现的。
- 是否允许null值:允许所有元素,包括null。
- 是否是线程安全的:不是线程安全的。
- 迭代器: 迭代器是fast-fail,但是迭代器的快速失败行为不能得到保证。
- 运行时间:在get,set,size等操作中,都是以常数时间运行,而add操作需要O(n)时间运行。
ArrayList的定义
1 | public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable |
- ArrayList
:支持泛型的存储模式。 - extends AbstractList
:继承于AbstractList,继承了其中的方法,方便操作。 - implements List
:实现了List接口,与继承AbstractList作用相同,实现该接口提供的方法,方便了实现。但是据开发这个collection 的作者Josh说:这其实是一个mistake,因为他写这代码的时候觉得这个会有用处,但是其实并没什么用,但因为没什么影响,就一直留到了现在。 - implements RandomAccess:实现了RandomAccess接口,表明支持固定时间的快速随机访问,这也是其在get和set方法时已固定时间运行的原因
- implements Cloneable:实现了Cloneable接口,内部可以调用clone()方法来返回实例的浅拷贝(shallow copy)。
- implements Serializable:实现了Serializable接口,表明该类时可以序列化的。
静态全局变量
1 | /** |
构造方法
指定初始容量
1 | /** |
- 如果传入的指定初始容量大于零,那就创建一个指定初始容量大小的数组用来存放数据
- 如果指定的初始等于零,则使用静态全局变量中的空数组EMPTY_ELEMENTDATA
- 如果指定的初始为负数,抛出异常
无指定初始容量
1 | /** |
传入集合初始化
1 | /** |
核心方法
trimToSize 方法
1 | /** |
该方法用于回收多余的内存。也就是说一旦我们确定集合不在添加多余的元素之后,调用 trimToSize() 方法会将实现集合的数组大小刚好调整为集合元素的大小。
注意:该方法会花时间来复制数组元素,所以应该在确定不会添加元素之后在调用。
ensureCapacity 方法
1 | /** |
grow 方法
1 | /** |
newCapacity 方法
1 | /** |
总结来说,对于数组容量扩容过程如下:
- 先确定三个变量:传入的所需的最小容量(minCapacity),旧容量(oldCapacity)也就是当前现在数组的长度,默认的新的容量(newCapacity)是旧容量的1.5倍。
- 对比minCapacity和newCapacity,如果对比minCapacity大于等于(>=)newCapacity,那么进入3,否则进入5。
- 如果elementData是只进行初始化,但是还没有存入数据的数组,那么它的长度肯定是0,所以这种情况下上面得到的oldCapacity和newCapacity是0,因此取默认初始容量(16)和minCapacity中的较大值,作为扩容后的容量。否则进入4。
- 判断如果传入的minCapacity是负数,那么抛出异常。否则将其作为扩容后的容量。
- 如果newCapacity小于等于MAX_ARRAY_SIZE(Integer.MAX_VALUE-8),那么newCapacity就是扩容大小,也就是扩容1.5倍。否则进行6。
- 如果newCapacity大于minCapacity,但是minCapacity其实是负数,那么直接抛出异常。否则再次判断minCapacity与MAX_ARRAY_SIZE的大小关系,如果minCapacity也大于MAX_ARRAY_SIZE,那么newCapacity和minCapacity都大于了MAX_ARRAY_SIZE,就把数组扩容为Integer.MAX_VALUE。否则进行7。
- 否则就只有newCapacity大于MAX_ARRAY_SIZE,而minCapacity小于等于MAX_ARRAY_SIZE,则数组扩容为MAX_ARRAY_SIZE。
size 方法
1 | /** |
isEmpty 方法
1 | /** |
contains 方法
1 | /** |
indexOf 于 lastIndexOf 方法
1 | /** |
1 | /** |
该方法需要遍历整个数组,寻找对应的元素的下标,所以时间复杂度为O(N)。
clone 方法
1 | /** |
该方法只返回此ArrayList实例的浅拷贝,元素本身不被复制。
toArray 方法
1 | /** |
1 | /** |
toArray 方法主要有两种方式,一种是无参方法,直接返回包含此列表中所有元素的数组;另一种是传入一个数组,然后把此列表中所有元素复制到该数组中,然后返回该数组。
get 方法
1 | /** |
set 方法
1 | /** |
add 方法
将指定的元素追加到此列表的末尾
1 | /** |
内部的add方法添加元素
1 | /** |
在指定位置插入指定的元素
1 | /** |
总结来说,如果在指定位置插入指定的元素,因为要移动指定位置后面的所有元素,那么O(N)的时间;如果将指定的元素追加到此列表的末尾,那么仅花费常数的时间,但是如果数组需要扩容的话,将花费时间对数组进行扩容,所以尽量在初始化该List时就指定好容量大小。
remove 方法
删除指定位置的元素
1 | /** |
删除第一个出现的指定元素
1 | /** |
fastRemove 方法
1 | /** |
clear 方法
1 | /** |
addAll 方法
将指定集合中的所有元素追加到列表的末尾
1 | /** |
从指定的位置开始,将指定集合中的所有元素插入到此列表中。
1 | /** |
removeAll 与 retainAll 方法
removeAll 方法
1 | /** |
retainAll 方法
1 | /** |
batchRemove 方法
1 | /** |
这里总结一下removeAll,retainAll和addAll方法之间的关系吧:
- removeAll 方法就是把存在于指定的集合中的元素全部删除掉,也就是求补集。
- retainAll 方法就是把不存在于指定的集合中的元素全部删除掉,也就是求交集。
- addAll 方法就把不存在于指定的集合中的元素全部添加到列表中,也就是求并集。
subList 方法
1 | /** |
所以总结来说,尽量不要使用subList方法,如果要使用的话,一定要注意下面几点使用方法:
- 千万不要再对原 List 进行任何改动的操作(例如: 增删改), 查询和遍历倒是可以. 因为如果对原 List 进行了改动, 那么后续只要是涉及到子 List 的操作就一定会出问题. 而至于会出现什么问题呢? 具体来说就是:
(1) 如果是对原 List 进行修改 (即: 调用 set() 方法) 而不是增删, 那么子 List 的元素也可能会被修改 (这种情况下不会抛出并发修改异常).
(2) 如果是对原 List 进行增删, 那么此后只要操作了子 List , 就一定会抛出并发修改异常. - 千万不要直接对子 List 进行任何改动的操作(例如: 增删改), 但是查询和间接改动倒是可以. 不要对子 List 进行直接改动, 是因为如果在对子 List 进行直接改动之前, 原 List 已经被改动过, 那么此后在对子 List 进行直接改动的时候就会抛出并发修改异常.
- 如果要进行操作,则使用例如:List
subList = new ArrayList<>(list.subList(2, list.size())); 的方法,把分割出来的数组转化为一个新的列表,在新的列表基础上操作就不会对原列表产生任何影响。
补充
考虑一点:elementData设置成了transient,那ArrayList是怎么把元素序列化的呢?
1 | private void writeObject(java.io.ObjectOutputStream s) |
查看writeObject()方法可知,先调用s.defaultWriteObject()方法,再把size写入到流中,再把元素一个一个的写入到流中。
一般地,只要实现了Serializable接口即可自动序列化,writeObject()和readObject()是为了自己控制序列化的方式,这两个方法必须声明为private,在java.io.ObjectStreamClass#getPrivateMethod()方法中通过反射获取到writeObject()这个方法。
在ArrayList的writeObject()方法中先调用了s.defaultWriteObject()方法,这个方法是写入非static非transient的属性,在ArrayList中也就是size属性。同样地,在readObject()方法中先调用了s.defaultReadObject()方法解析出了size属性。
elementData定义为transient的优势,自己根据size序列化真实的元素,而不是根据数组的长度序列化元素,减少了空间占用。
总结
- ArrayList内部使用数组存储元素,当数组长度不够时进行扩容,每次加一半的空间,ArrayList不会进行缩容;
- ArrayList支持随机访问,通过索引访问元素极快,时间复杂度为O(1);
- ArrayList添加元素到尾部极快,平均时间复杂度为O(1);
- ArrayList添加元素到中间比较慢,因为要搬移元素,平均时间复杂度为O(n);
- ArrayList从尾部删除元素极快,时间复杂度为O(1);
- ArrayList从中间删除元素比较慢,因为要搬移元素,平均时间复杂度为O(n);
- ArrayList支持求并集,调用addAll(Collection<? extends E> c)方法即可;
- ArrayList支持求交集,调用retainAll(Collection<? extends E> c)方法即可;
- ArrayList支持求单向差集,调用removeAll(Collection<? extends E> c)方法即可;