HashMap的数据结构
先介绍一点基础结构
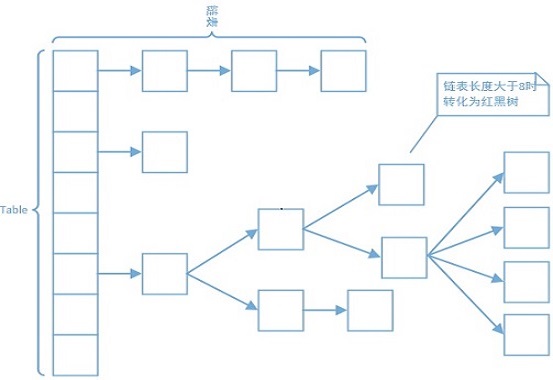
HashMap的基础结构是由数组(Node<K,V>[] table)+ 链表 + 红黑树组成的,因为我对红黑树不太了解,所以就没有看后面红黑树部分的东西(1400行之后的代码基本全是在说红黑树部分的),下面就没有讲述红黑树部分的内容。
数组的每个下标位置储存的是Node结点, 在Javadoc中把存放数据的table数组的每个下表称作bin(桶),数组每个下标的一开始存放的是链表,当链表长度大于等于(>=)8的时候,会将链表转换为红黑树。
顶部注释:
HashMap是Map接口基于哈希表的实现。这种实现提供了所有可选的Map操作,并允许key和value为null(除了HashMap是unsynchronized的和允许使用null外,HashMap和HashTable大致相同。)。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
此实现假设哈希函数在桶内适当地分布元素,为基本实现(get 和 put)提供了稳定的性能。迭代 collection 视图所需的时间与 HashMap 实例的“容量”(桶的数量)及其大小(键-值映射关系数)成比例。如果遍历操作很重要,就不要把初始化容量initial capacity设置得太高(或将加载因子load factor设置得太低),否则会严重降低遍历的效率。
HashMap有两个影响性能的重要参数:初始化容量initial capacity、加载因子load factor。容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。initial capacityload factor就是当前允许的最大元素数目,超过initial capacityload factor之后,HashMap就会进行rehashed操作来进行扩容,扩容后的的容量为之前的两倍。
通常,默认加载因子 (0.75) 在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少rehash操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生rehash 操作。
如果很多映射关系要存储在 HashMap 实例中,则相对于按需执行自动的 rehash 操作以增大表的容量来说,使用足够大的初始容量创建它将使得映射关系能更有效地存储。
注意,此实现不是同步的。如果多个线程同时访问一个哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。(结构上的修改是指添加或删除一个或多个映射关系的任何操作;仅改变与实例已经包含的键关联的值不是结构上的修改。)这一般通过对自然封装该映射的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedMap 方法来“包装”该映射。最好在创建时完成这一操作,以防止对映射进行意外的非同步访问,如下所示:
Map m = Collections.synchronizedMap(new HashMap(…));由所有此类的“collection 视图方法”所返回的迭代器都是fail-fast 的:在迭代器创建之后,如果从结构上对映射进行修改,除非通过迭代器本身的remove方法,其他任何时间任何方式的修改,迭代器都将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不冒在将来不确定的时间发生任意不确定行为的风险。
注意,迭代器的快速失败行为不能得到保证,一般来说,存在非同步的并发修改时,不可能作出任何坚决的保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常的程序的做法是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测bug。
此类是 Java Collections Framework 的成员。
从上面的内容可以总结出以下几点:
- 底层: HashMap是Map接口基于哈希表实现的。
- 是否允许null: HashMap允许key和value为null。
- 是否有序:HashMap不保证映射到顺序,特别是它不保证顺序恒久不变。
- 两个影响HashMap性能的参数: 初始化容量initial capacity、加载因子load factor。
- 每次扩容大小:扩容后的的容量为之前的两倍。
- 初始化容量对性能的影响: 不应设置的太小,容量小虽然可以节省空间,但是可能会导致频繁的扩容,扩容操作非常消耗时间;也不应该设置的太大,容量大会导致严重降低遍历的效率以及内存空间的浪费。总结来说就是:小了会增大时间开销(频繁的扩容);大了会增大空间开销和时间开销(降低遍历效率)。
- 加载因子对性能的影响: 0.75是一个折中的值,加载因子过高虽然减少了空间开销,但是也增加了查询到成本;而加载因子过低会导致频繁的扩容。
- 是否同步: HashMap不是同步的。
- 迭代器: 迭代器是fast-fail,但是迭代器的快速失败行为不能得到保证。
HashMap的定义
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable - HashMap<K,V>:HashMap是以key-value形式存储数据。
- extends AbstractMap<K,V>: 继承于AbstractMap,大大减少了实现Map接口时需要的工作。
- implements Map<K,V: 实现了Map接口,提供所有可选的Map操作。
- implements Cloneable:实现了Cloneable接口,内部可以调用clone()方法来返回实例的浅拷贝(shallow copy)。
- implements Serializable:实现了Serializable接口,表明该类时可以序列化的。
静态全局变量
1 | /** |
静态内部类 Node
1 |
|
静态工具
hash方法详解
1 | /** |
主要分为三步:
- 取hashCode的值: key.hashCode()。调用Object. hashCode() 方法,该方法根据一定规则将与对象相关的信息,例如对象的存储地址,对象的字段等,映射成与一个32位 int 类型的值,这个数值称作为hash值。
- 让高位参与运算: h>>>16 。将得到的hash值无符号右移十六位,空出来的高位补零。
- 取模运算: (n-1) & hash 。 为了让数组元素分布均匀,把hash值对数组长度-1取余,也就是hash%n,得到在数组中保存的位置下标。
为什么要这样做的理由:

整个过程如上图所示,将原本的32位的hash值右移16位,然后与原值进行异或运算,是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。
看到这里有个疑问,为什么要做异或运算?
设想一下,如果n很小,假设为16的话,那么n-1即为15(0000 0000 0000 0000 0000 0000 0000 1111),这样的值如果跟hashCode()直接做与操作,实际上只使用了哈希值的后4位。如果当哈希值的高位变化很大,低位变化很小,这样很容易造成碰撞,所以把高低位都参与到计算中,从而解决了这个问题,而且也不会有太大的开销。
然后将得到的最终的hash值对数组长度-1取余,就可以得到在数组中保存的位置下标。这也是为什么要保证数组的长度总是2的n次方的理由。当数组长度length总是2的n次方时,(n - 1) & hash == hash % n,但是位运算的速度更快,因此保证效率更高。
comparableClassFor方法解读
1 | /** |
如注释所示,传参传入一个对象,当对象x的类型为X,并且X实现了Comparable接口(比较的参数本身必须为X类本身)时,返回x的运行时类型,否则返回null。
接下来分析这个方法的每行代码。
- instanceof
1
x instanceof Comparable
instanceof可以理解为是某种类型的实例。不论是运行时类型,或者是他的父类、它实现的接口、他的父类实现的接口、甚至是他父类的父类的父类实现的接口的父类的父类,总之,只要在继承链上有这个类型就可以了。
- getClass()
1
c = x.getClass()
与instanceof相应对的是getClass()方法,无论该对象如何转型,该方法返回的只会是它的运行时类型,可以简单的理解为它的实际类型,也就是new它的时候的类型。
有一种例外情况:匿名对象。当匿名对象调用该方法时,返回的是依赖它的对象的运行时类型,并且以1,2,3…的索引区分。
1 | public class Demo { |
- getGenericInterfaces()
1
ts = c.getGenericInterfaces()
getGenericInterfaces()方法返回的是该对象的运行时类型”直接实现”的接口,这意味着:
- 返回的一定是接口
- 必然是该类型自己直接实现的接口,继承过来的不算
getGenericSuperclass()和getSuperclass()
这两个方法虽然没有出现在上述代码中,但是也顺便说一下:- getGenericSuperclass()返回的是父类的直接类型,不包括泛型参数。
- getSuperclass()返回的是包括泛型参数的父类类型,但是注意,如果子类在继承父类时,没有实现(声明)父类的泛型,那么这时候子类是没有泛型参数的。
ParameterizedType
1
t instanceof ParameterizedType
ParameterizedType是Type接口的子接口,表示实现了泛型参数的类型。需要注意:
- 如果直接用Bean对象 instanceof ParameterizedType,结果都是false。
- Class对象不能 instanceof ParameterizedType,编译会报错。
- 只有用Type对象 instanceof ParameterizedType ,才能得到想要的比较结果。可以理解为:一个Bean类不会是ParameterizedType,只有代表这个Bean类的类型(Type)才有可能是ParameterizedType。
- 实现泛型参数,必须给泛型传入参数,例如:class Child2<A,B> extends Super<A,B>{} ;只声明泛型而不实现,例如:class Child3<A,B> extends Super{} , 对比结果为false。
- getRawType()
1
((p = (ParameterizedType) t).getRawType()
该方法返回实现了这个类型的类或者接口,即去掉了泛型参数部分的类型对象。
- getActualTypeArguments()
1
as = p.getActualTypeArguments()
该方法与getRawType()相对应,以数组形式返回泛型的参数列表。
- 当参数是真实类型时,打印的是全类名
- 当参数是另一个新声明的泛型参数时,打印的是代表该泛型类型的符号。
所以总结comparableClassFor(Object x)方法的实现为:
1 | static Class<?> comparableClassFor(Object x) { |
compareComparables 方法
1 | /** |
tableSizeFor 方法
1 | /** |
该方法是为了在构造函数中,把传入的指定容量转化为2的幂次方的整数,保证HashMap的容量为2的幂次方。
字段
1 | /** |
核心方法
构造方法
指定初始化容量和加载因子
1 | /** |
指定初始化容量
1 | /** |
默认的初始化容量和加载因子
1 | /** |
使用与指定映射相同的映射
1 | /** |
putMapEntries方法
1 | /** |
size方法
1 | /** |
isEmpty方法
1 | /** |
get方法
1 | /** |
getNode方法
1 | /** |
get和getNode方法总结
从上面的源码中可以看出,get方法可以分为三个步骤:
- 通过hash方法得到key的hash值(hash方法在上面有详细的解释)
- 将上一步得到的key的hash值和key传入getNode方法,得到该key对应的Node
- 如果该key对应的Node为空,则返回null,否则返回Node中的value,如果Node中的value为空,那么也返回null
getNode方法步骤如下:
- 判断HashMap中存放数据的table的是否初始化,是否有数据(长度是否为0),根据key的hash值计算得到的该key在table中对应得下标处是否有结点;只有三种情况全部满足的情况下,才进入下标处得链表/红黑树查找,否则直接返回null
- 检查下标处的头节点是否匹配,匹配则返回该节点,否则检查头结点后面的结点
- 判断桶中存放数据的的数据结构是红黑树还是链表,如果桶中的数据结构是红黑树,则用红黑树的方法查找。
- 如果是链表则从链表的第二个节点开始,遍历链表的每一个结点查找,找到就返回对应的节点。
- 如果红黑树或链表的遍历中都没有找到,那么就返回null,代表不存在该节点。
containsKey方法
1 | /** |
该方法其实本质调用了getNode的方法,判断是否存在以key的键的结点,如过Node存在则返回true,否则返回false。
put方法
1 | /** |
put方法可以分为三个步骤:
- 通过hash方法获取到传入的key的hash值(hash方法在上面有详细的解释)
- 通过putVal方法放入map中
- 返回putVal方法的结果
putVal方法
1 | /** |
总结putVal方法,共有如下几个步骤:
- 判断table数组是否初始化,如果没有就进行初始化
- 根据key的hash值计算得到的下标处,如果该下标处没有节点,那么就新建一个结点放入桶中
- 如果该下标处已经存在节点,那么就代表发生了碰撞,开始对链表/红黑树进行遍历
- 如果第一个结点的key就与传入的key相等,那么就把这个结点记录下来,在后面覆盖;
- 如果第一个key没有碰撞,而且桶中的结构是树,那么就调用相应的树的方法放置键值对, 如果第一个key没有碰撞,而且桶中的结构是链表,那么就遍历链表
- 当遍历到链表尾部,新建节点然后插入链表尾部,然后判断链表长度,是否需要转化为红黑树,如果在遍历链表中发生了key相等,那么就把这个结点记录下来,在后面覆盖;
- 如果发生了key相等的情况,就对结点旧值覆盖,然后把旧值返回
- 如果没有发生key相等的情况,而是插入了新的结点,那么modCount和size都加一,判断size是否超过阈值,超过就扩容
- 返回null
resize方法
当像HashMap中不断地添加元素的时候,元素的数量就会增加,数量增大就不避免的增大了碰撞的概率。所以当元素的数量达到一个阈值的时候,就对HashMap进行扩容。当然数组是无法自动扩容的,扩容方法使用一个新的数组代替已有的容量小的数组。
resize方法非常巧妙,因为每次扩容都是翻倍,保证了数组大小为2得整数次方,同时与原来计算(n-1)&hash的结果相比,节点要么就在原来的位置,要么就被分配到“原位置+旧容量”这个位置。
1 | /** |
resize方法总结:
总体可以两大部分:
- 首先是计算新桶数组的容量 newCap 和新阈值 newThr
- 将原集合的元素重新映射到新集合中
细节的过程如下:
remove方法
1 | /** |
removeNode方法
1 | /** |
总结removeNode方法为:
- 如果数组table为空或key映射到的桶为空,直接返回null。
- 如果key映射到的桶上第一个Node的就是要删除的Node,记录下来。
- 如果桶内不止一个Node,且桶内的结构为红黑树,记录key映射到的Node。
- 桶内的结构不为红黑树,那么桶内的结构就肯定为链表,遍历链表,找到key映射到的Node,记录下来。
- 如果被记录下来的Node不为null,则使用数据结构相对应的删除方法删除Node,++modCount;–size;
- 返回被删除的node。
clear方法
1 | /** |
containsValue方法
1 | /** |
一些其他方法
keySet方法
1 | /** |
values方法
1 | /** |
entrySet方法
1 | /** |
clone方法
1 | /** |
回调方法
1 | // 允许LinkedHashMap后操作的回调 |
这三个回调方法在之前方法中出现过,它们的作用就是在给LinkedHashMap时继承使用,在HashMap中没有实质的作用,所以方法体为空。LinkedHashMap 是 HashMap 的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用 LinkedHashMap。
个人总结
- 可以看出HashMap在扩容时的操作是很花费时间的,所以尽量在创建HashMap的时候就把容量指定,避免扩容操作,增大运行时间。
- 不知道有没有人想过,为什么在很多方法中,都是新建局部变量,然后把相应的数据赋给局部变量,而不是直接使用全局变量呢?例如下面这样:
1
2
3
4
5Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
tab = table;
n = tab.length;
first = tab[(n - 1) & hash];
k = first.key;
个人猜测这样做的原因是:
新定义的变量在栈顶,出栈快,局部变量,用完就销毁,提高速度,也不额外占用内存。
当然还有一种可能是因为HashMap不是线程安全的,所以可能因为使用全局变量的话会导致数据差异的原因,所以在每个方法里面,把这个方法开始的时候的数据保存下来,只对当前保存下来的数据进行运算,不影响其他线程和方法对数据的使用,同时也体现了高明的严谨性。
当然这只是个人猜测的结果,具体的原因也没有查到,所以这里就算是一个遗留的小问题吧。