LinkedList的数据结构
LinkedList的底层数据结构是基于双向链表实现的,如图: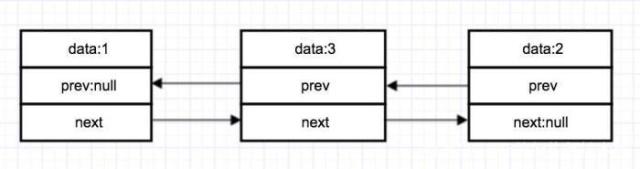
因为链表在物理内存上可以是不连续的,所以理论上,只要计算机的内存足够大的情况下,LinkedList的长度可以无限长。
顶部注释
双向链表实现了List和Deque接口。 实现所有可选列表操作,并允许所有元素(包括null )。
所有的操作都能像双向列表一样预期。 索引到列表中的操作将从开始或结束遍历列表,以更接近指定的索引为准。请注意,此实现不同步。 如果多个线程同时访问链接列表,并且至少有一个线程在结构上修改列表,则必须在外部进行同步。 (结构修改是添加或删除一个或多个元素的任何操作;仅设置元素的值不是结构修改。)这通常通过在自然封装列表的对象上进行同步来实现。 如果没有这样的对象存在,列表应该使用Collections.synchronizedList方法“包装”。 这最好在创建时完成,以防止意外的不同步访问列表:
List list = Collections.synchronizedList(new LinkedList(...));该类的iterator和listIterator方法返回的迭代器是fail-fast的 :如果列表在迭代器创建后的任何时间进行结构修改,除了通过Iterator自己的remove或add方法外,迭代器将抛出一个ConcurrentModificationException 。 因此,面对并发修改,迭代器将快速而干净地失败,而不是在未来未确定的时间冒着任意的非确定性行为。
请注意,迭代器的故障快速行为无法保证,因为一般来说,在不同步并发修改的情况下,无法做出任何硬性保证。 失败快速的迭代器ConcurrentModificationException扔掉ConcurrentModificationException 。 因此,编写依赖于此异常的程序的正确性将是错误的: 迭代器的故障快速行为应仅用于检测错误。
从上面LinkedList的源码顶部注释可以总结以下几点:
- 底部实现:双向链表。
- 是否允许null值:允许所有元素,包括null。
- 线程安全:线程不安全。
- 迭代器:迭代器是fast-fail,但是迭代器的快速失败行为不能得到保证。
- 运行时间:因为是链表的实现,所以任何需要查询到操作都需要遍历链表,即O(n)的时间。
LinkedList的定义
1 | public class LinkedList<E> |
- LinkedList
:支持泛型的存储模式。 - extends AbstractSequentialList
:继承于AbstractSequentialList,继承了其中的方法,方便操作。 - implements List
:实现了List接口,实现该接口提供的方法,方便了实现。 - implements Deque
:实现了双端队列的接口,因此双向链表操作起来更方便。 - implements Cloneable:实现了Cloneable接口,内部可以调用clone()方法来返回实例的浅拷贝(shallow copy)。
- implements Serializable:实现了Serializable接口,表明该类是可以序列化的。
全局变量
1 | //记录元素个数的常量 |
构造方法
LinkedList只有两个构造方法:
1 | /** |
可以从上面的代码中看出,两个构造方法分别是无参方法和传入一个集合的方法。
无参方法的方法体为空,因为是链表结构,而链表的头指针和尾指针已经在上面定义过了,而且不同于数组结构,不需要指定大小和扩容,所以方便很多,因此无参方法什么都不需要做。
传入一个集合的构造方法使用addAll()方法将传入的集合按顺序添加到链表的尾部,addAll()方法可以的具体实现可以看下面的核心方法部分。
核心方法
getFirst和getLast方法
1 | /** |
根据代码可以看出,获取到first节点,如果列表中没有元素,所以列表是空的,first节点自然是null,所以抛出NoSuchElementException异常;否则返回first节点的数据。
1 | /** |
同getFirst方法很相似,获取到last节点的值,依旧判断last是否为空,为空则抛出异常;否则返回最后一个节点last的值。
removeFirst方法
1 | /** |
removeLast方法
1 | /** |
addFirst方法
1 | /** |
add和addLast方法
add和addLast方法中同是调用了linkLast方法,将新的元素添加到链表的尾部,二者的唯一却别就是add方法添加成功的话,会返回true表示插入成功,而addLast方法则无返回值,在内部实现上无任何区别。
1 | /** |
contains和indexOf方法
1 | /** |
size方法
1 | /** |
remove方法
remove方法有三个重载方法,分别是无参方法、传入下标和传入指定对象的方法。
remove(Object o)
1 | /** |
remove(int index)
1 | /** |
先看以下判断下标是否越界的checkElementIndex方法:
1 | private void checkElementIndex(int index) { |
在下标符合要求后,使用node方法查找到指定位置的节点:
1 | /** |
在使用node方法找到指定下标位置的节点之后,使用unlink方法将该节点删除掉,unlink方法在上面remove(Object o)方法中有讲过。
remove()
1 | /** |
lastIndexOf方法
1 | /** |
toArray方法
1 | /** |
队列操作的方法
因为Queue和Deque都是使用LinkedList实现的,所以这里也顺便提一下把,但是实际上有关队列操作的方法实则都是使用上面的核心方法实现的,所以这里就列一个表格对比一下:
- peek() :等于getFirst()方法,唯一区别就是当链表为空时,peek方法返回null,getFirst抛出异常。
- element():等于getFirst()方法。
- poll():等于removeFirst()方法,唯一区别就是当链表为空时,poll方法返回null,removeFirst抛出异常。
- remove():等于removeFirst()方法。
- offer():等于add()方法。
- offerFirst():等于addFirst()方法。
- offerLast():等于addLas()方法。
- peekFirst():等于peek()方法。
- peekLast():等于getLast()方法,唯一区别就是当链表为空时,peekLast方法返回null,getLast抛出异常。
- pollFirst():等于removeFirst()方法,唯一区别就是当链表为空时,pollFirst方法返回null,removeFirst抛出异常。
- pollLast():等于removeLast()方法,唯一区别就是当链表为空时,pollLast方法返回null,removeLast抛出异常。
- push():等于addFirst()方法.
- pop():等于removeFirst()方法。
- removeFirstOccurrence():等于remove()方法。
- removeLastOccurrence():等于removeLast()方法。
总结
总体来说,LinkedList的源码十分简单,从源码中可以简单得出以下几点:
- LinkedList的底层是双向链表。
- 有序。链表是有序的。
- 元素可重复,元素可为null。
- 随机访问效率低,增删效率高。